Theory of Space
Can Foundation Models Construct Spatial Beliefs Through Active Exploration?
🔥 Accepted by ICLR 2026 🔥
What is Theory of Space?
Theory of Space is the ability to build a mental map from partial views. We define it as three coupled abilities:
Construct
Actively explore and integrate partial observations into a globally consistent belief.
Revision
Revise the belief when new evidence conflicts with earlier assumptions.
Exploit
Use the current belief to answer spatial queries.
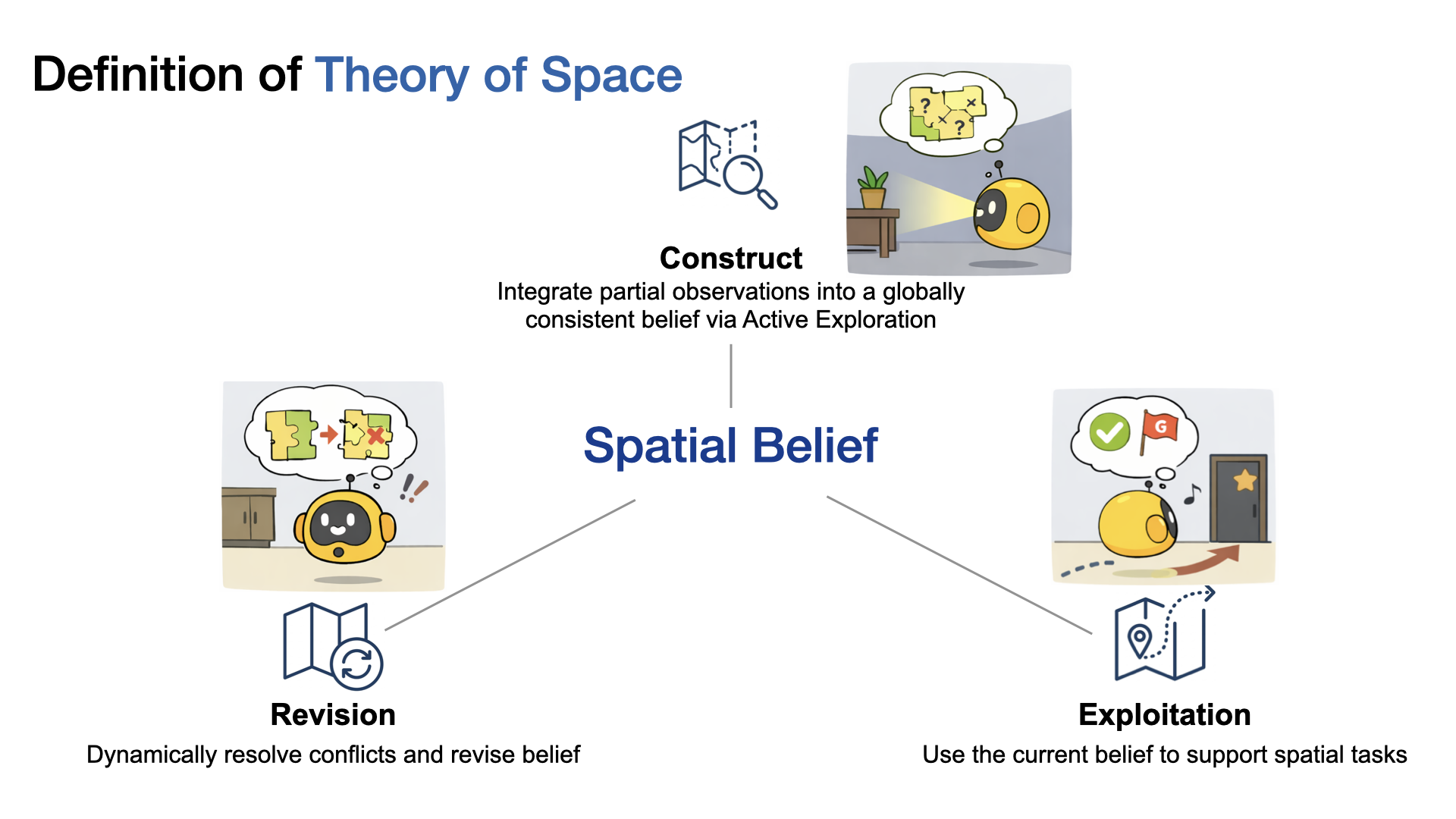
Theory of Space decomposes into constructing, revising, and exploiting an internal spatial belief.
We operationalize this by explicitly probing the agent’s cognitive map during exploration, not just its final answers. This exposes belief accuracy, uncertainty, and how the map evolves over time.
Why is this problem important?
- Active Exploration: Embodied agents must actively explore to construct spatial beliefs, unlike passive systems.
- Efficiency Challenge: Effective exploration requires efficient decision-making under uncertainty, prioritizing information gain.
Current Limitations: Multimodal models excel at passive tasks but struggle with active exploration under partial observability. Key bottlenecks include:
- Active vs. Passive Gap: Models significantly underperform in active settings compared to passive reasoning.
- Modality Gap: Vision-based performance lags behind text-based reasoning.
- Inefficiency: Models require far more actions than optimal proxies.
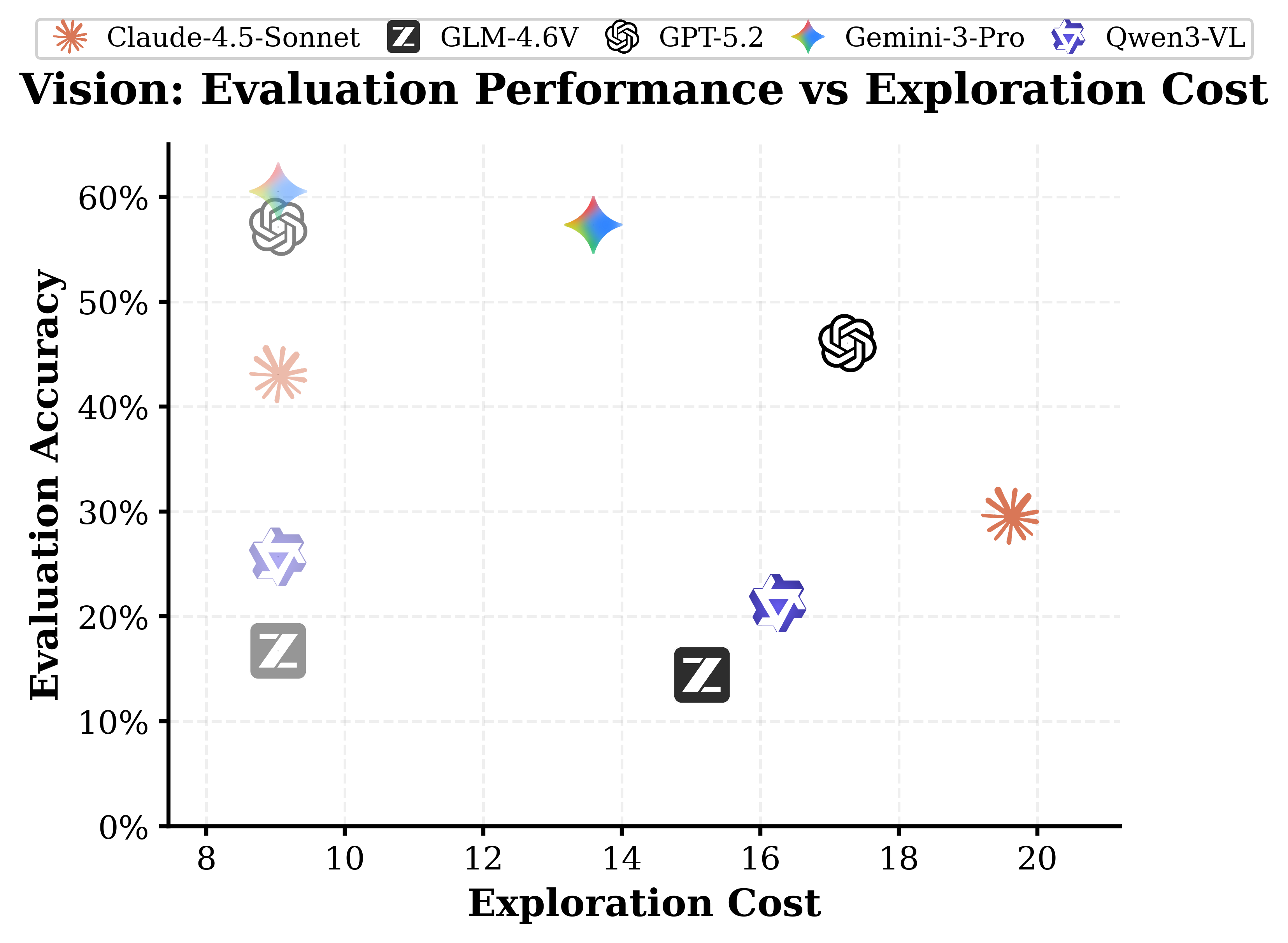
Cost vs. evaluation accuracy in VisionWorld; faded icons indicate passive logs (reasoning only).
What do we do?
We build a benchmark where models must explore and reveal their spatial beliefs. Text-based and vision-based worlds are paired so we can isolate reasoning vs exploration.
Exploration Environment
Procedurally generated multi-room layouts on N×M grid with paired environments:
- Text World: symbolic observations with direction/distance bins (pure reasoning)
- Vision World: egocentric RGB images from ThreeDWorld (perception + reasoning)
Action Space
Active Exploration Example
Step through the agent's interaction to see what it observes, chooses, believes, and how that aligns with the ground truth.
Move forward to inspect the door.
The agent sees a partial room view with a door to the front-left.
Task Suite
We evaluate how the learned map is used at two levels:
- Route-level tasks test egocentric, path-based reasoning.
- Survey-level tasks test allocentric, map-like reasoning.
Survey-level probes ask whether a model can infer unseen views and handle geometric transformations beyond memorized paths.
Task suite for Theory of Space covering route-level and survey-level belief.
Belief Revision
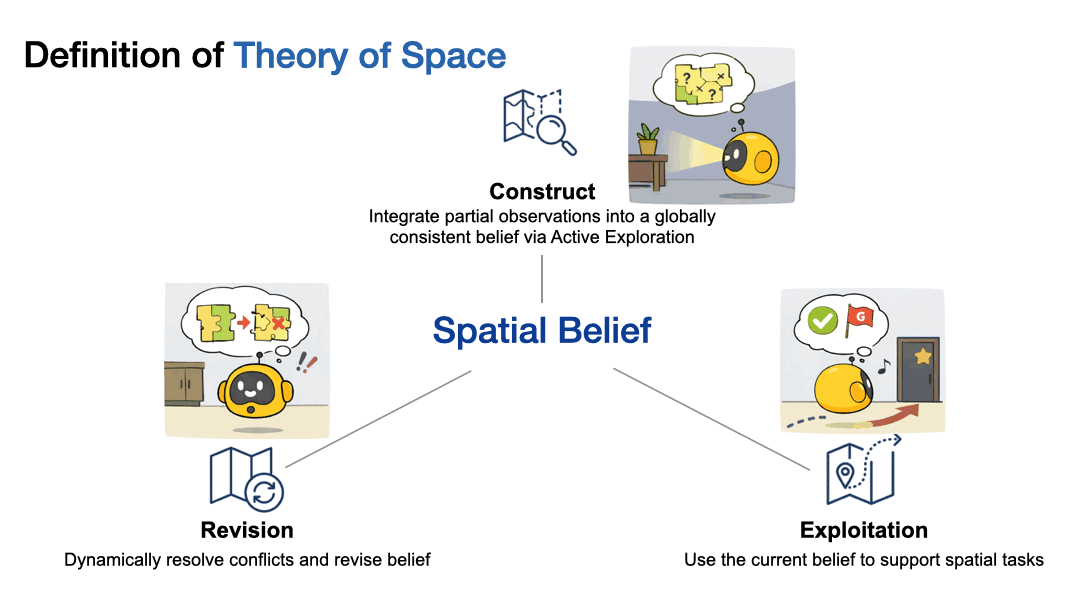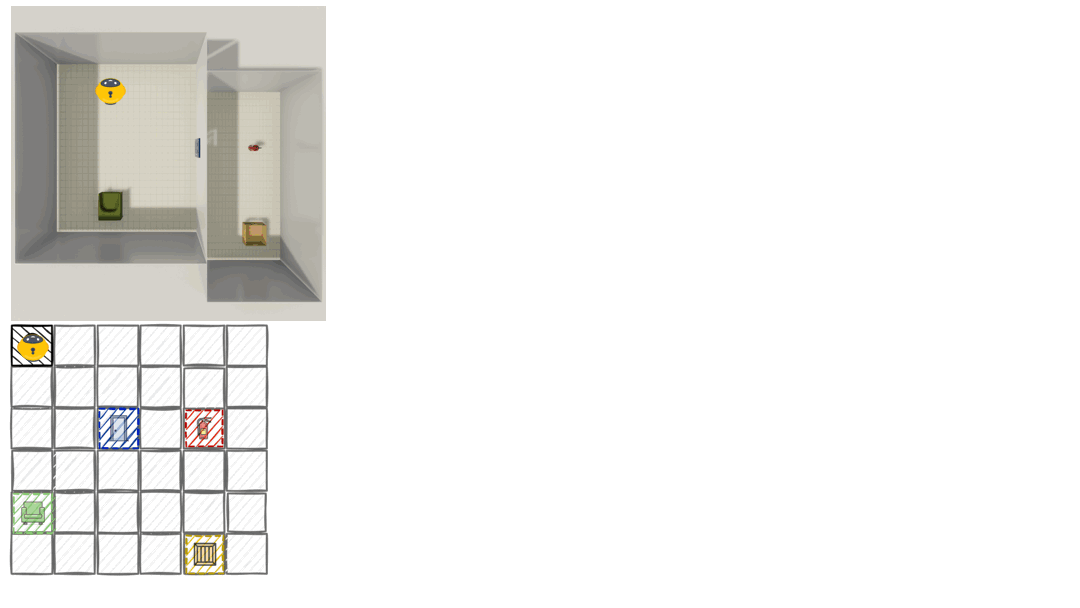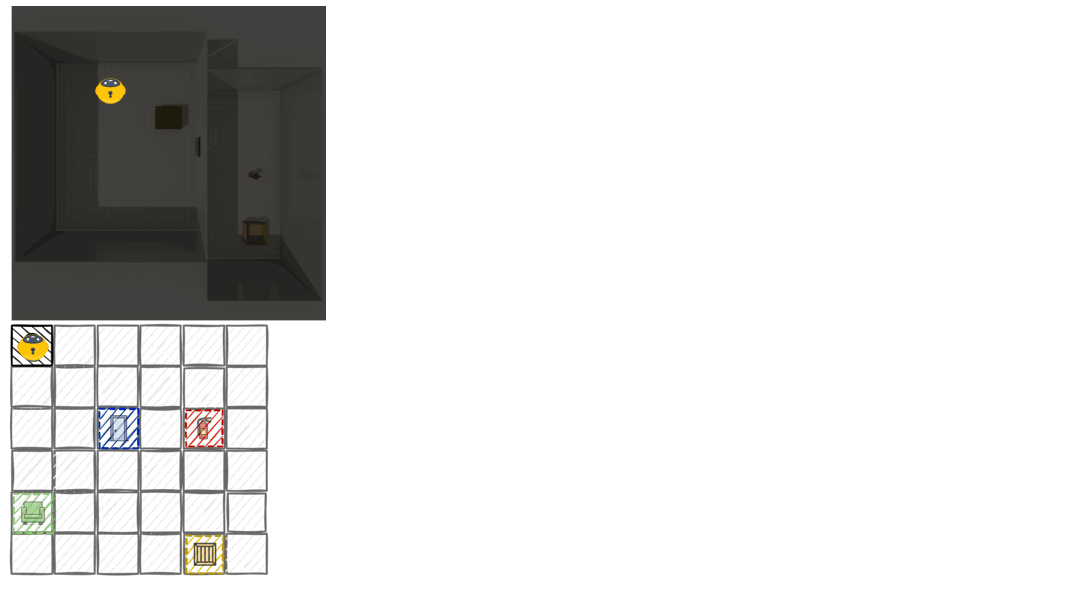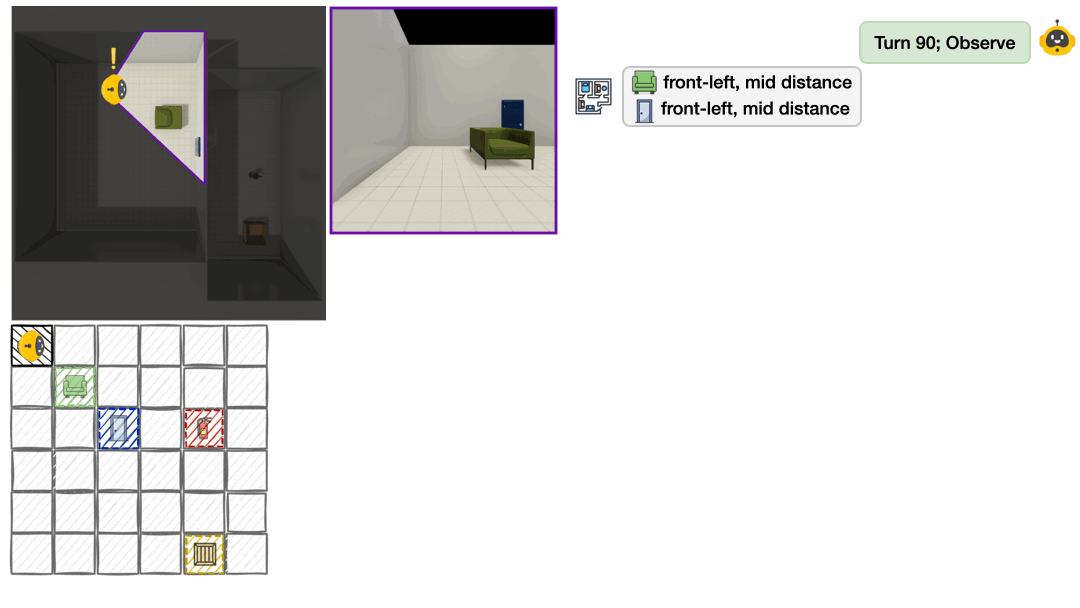
We introduce a dynamic perturbation task to probe Belief Revision. After exploration, objects are secretly relocated, creating a "false belief" that conflicts with new observations.
- Task: The agent must actively re-explore to identify changes and revise its map.
Disentangling Exploration from Reasoning
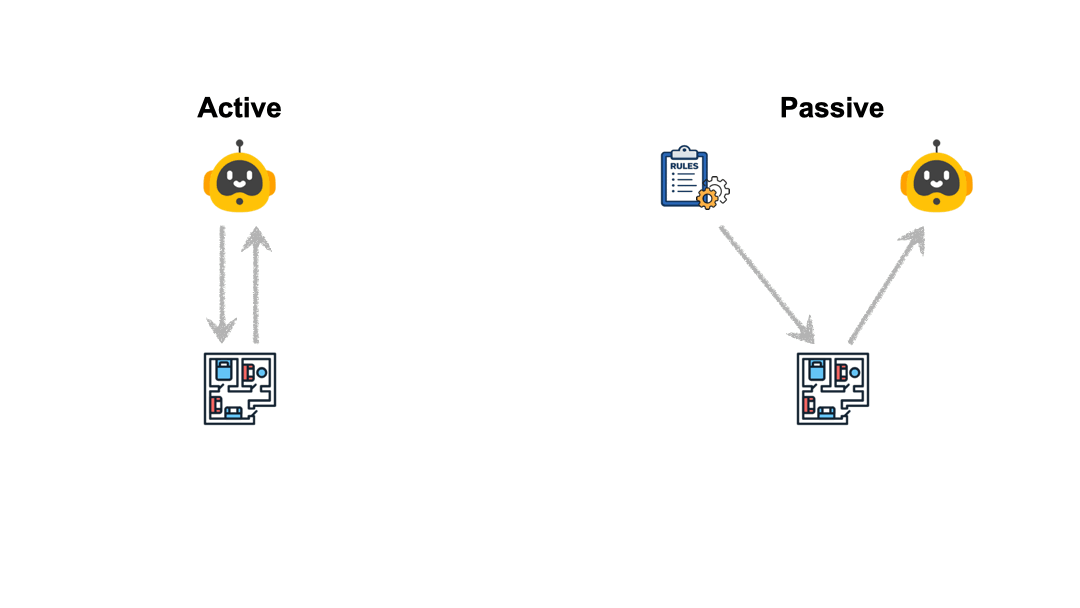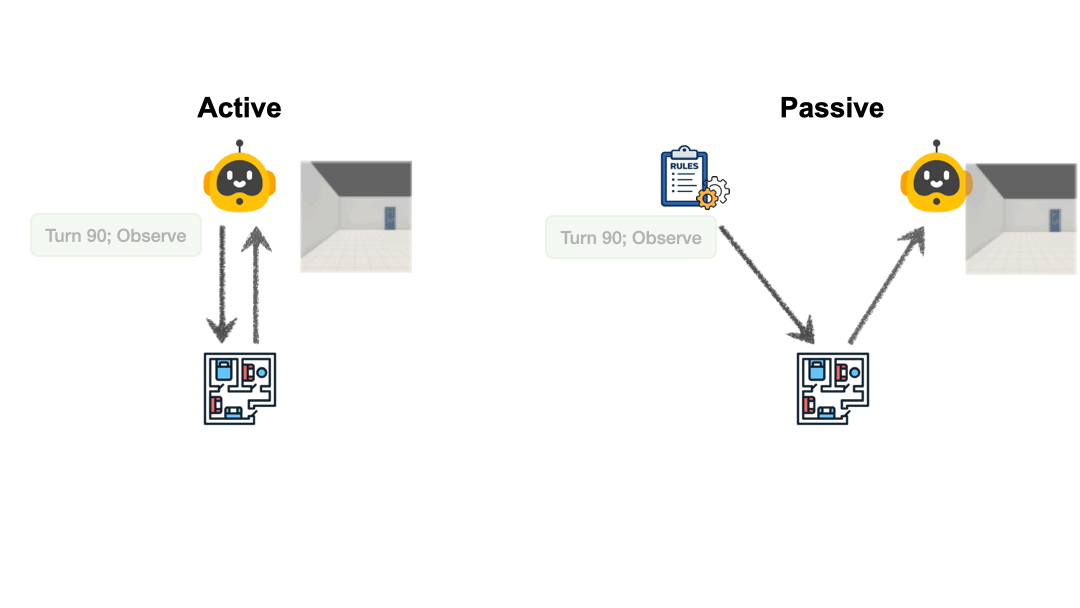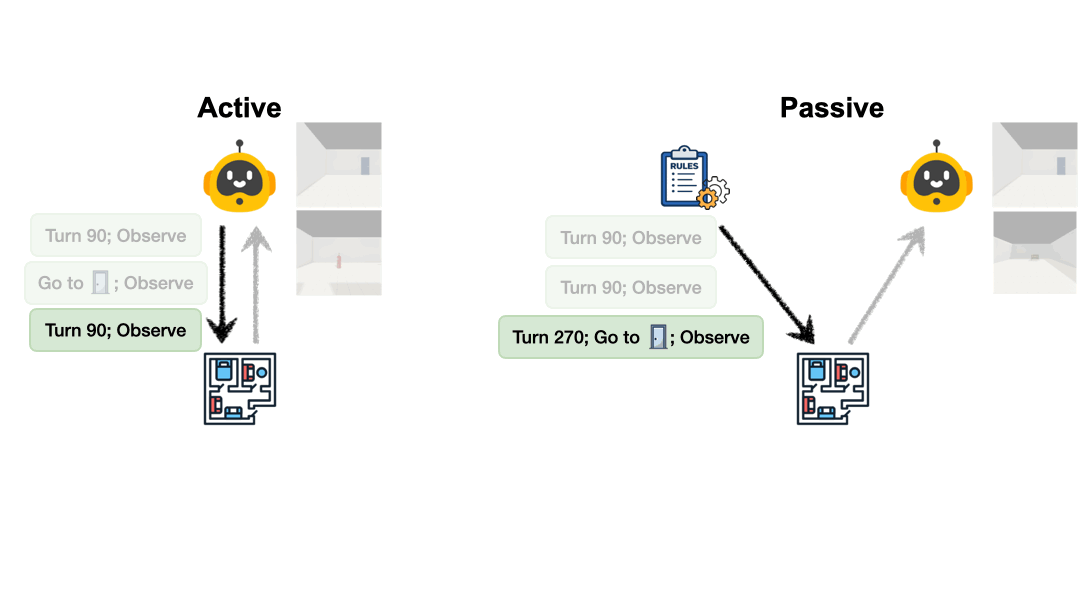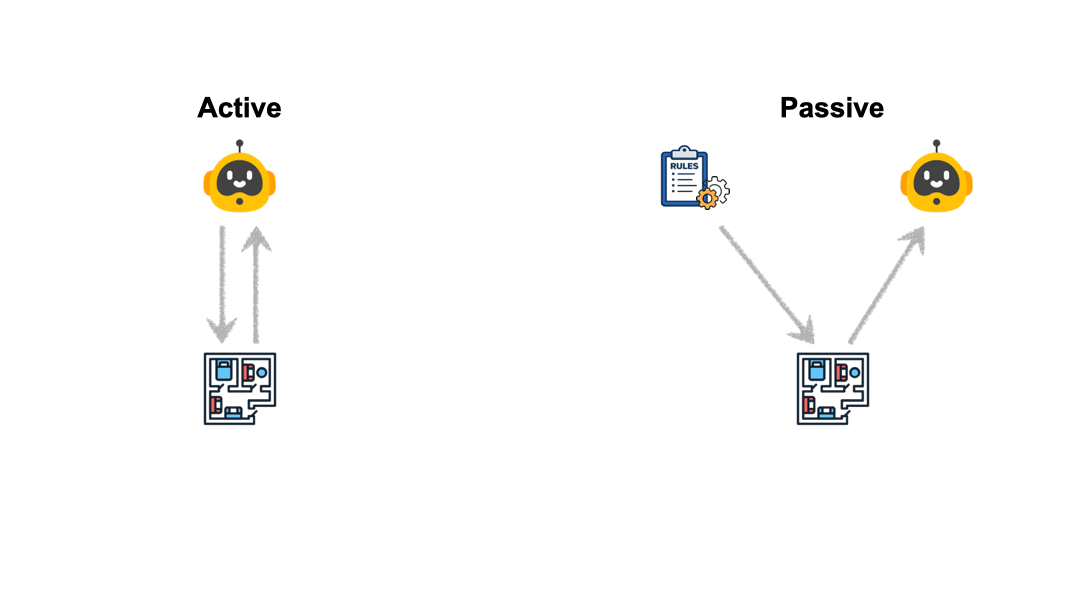
We disentangle exploration ability from reasoning ability using scripted proxy agents:
- SCOUT (vision): rotates 360° at each location for full coverage
- STRATEGIST (text): belief-driven policy to maximally reduce ambiguity
Active Exploration
Agent plans its own actions, balancing cost vs. information gain.
Passive Comprehension
Model reasons from proxy-collected logs, isolating reasoning from exploration.
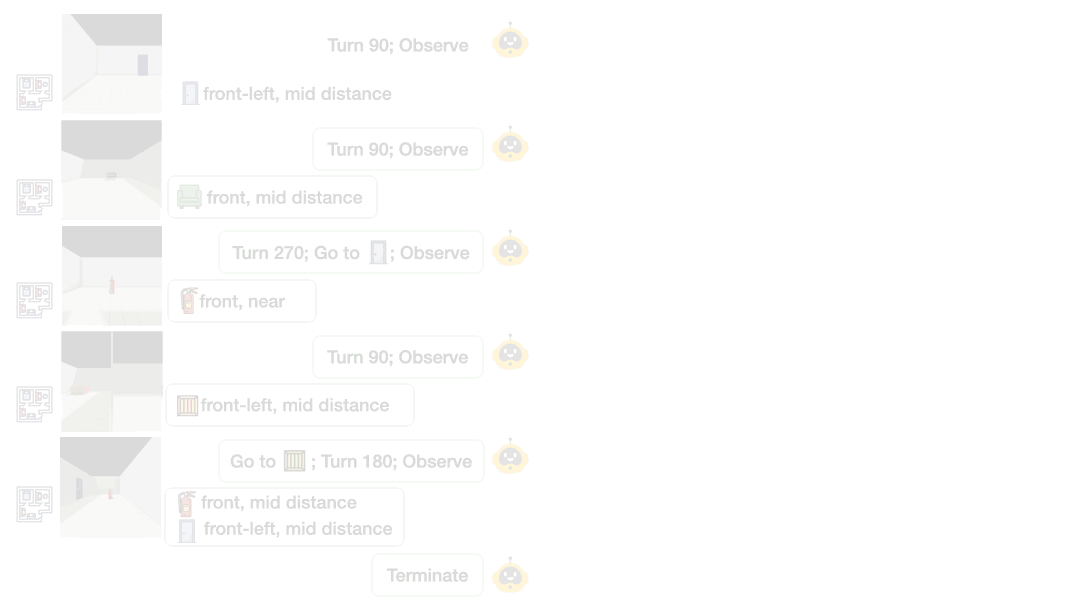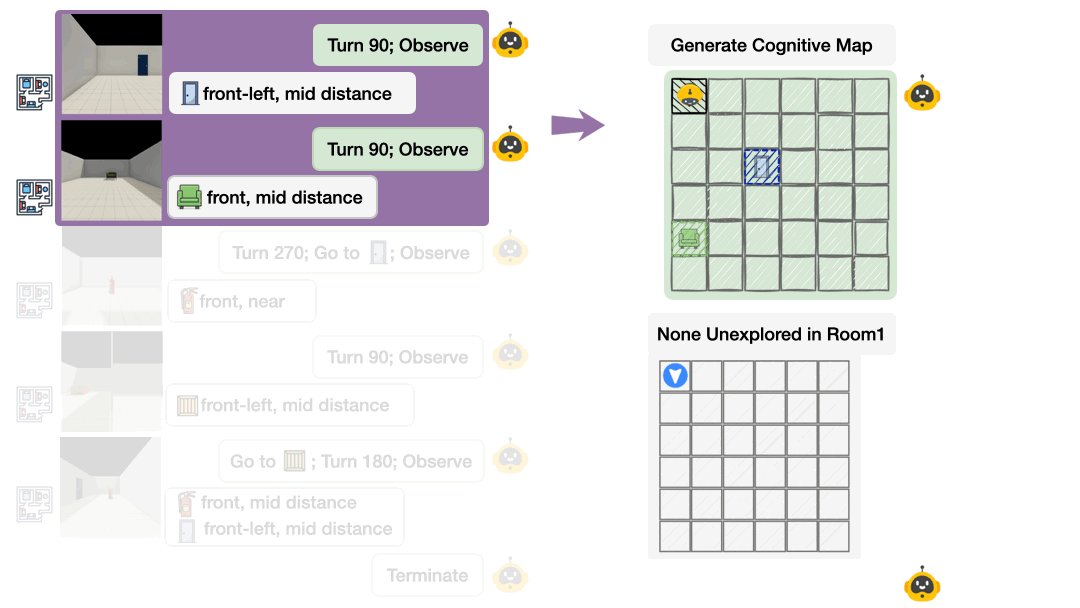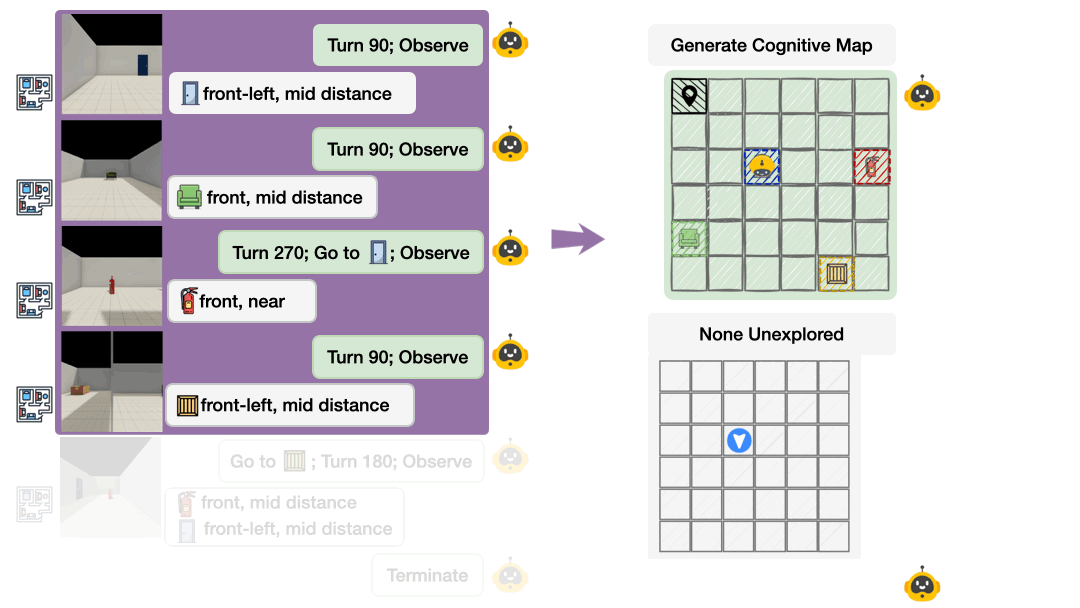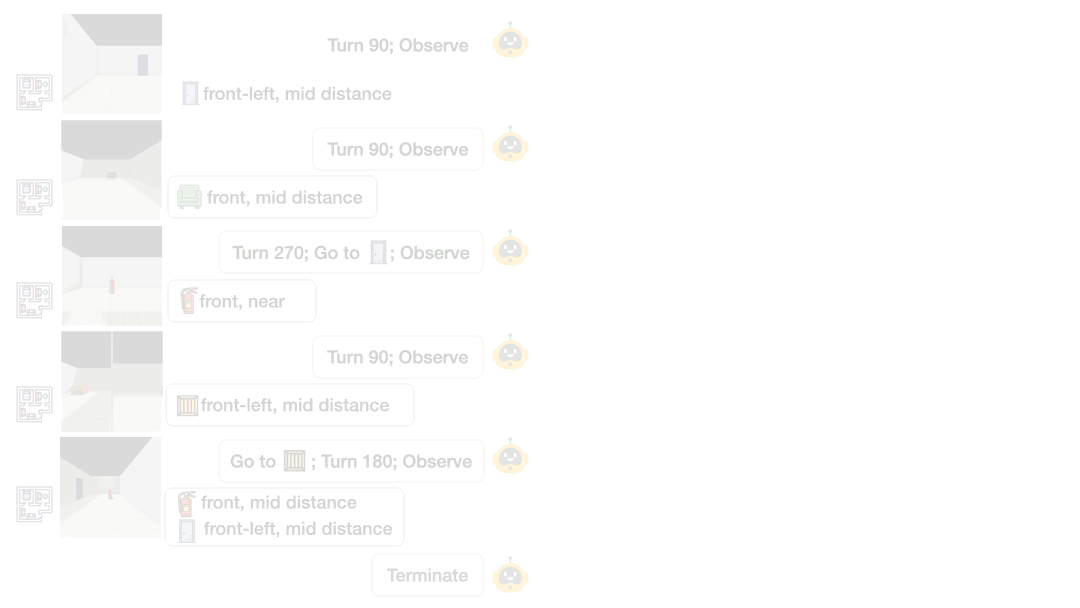
Probing Internal Belief
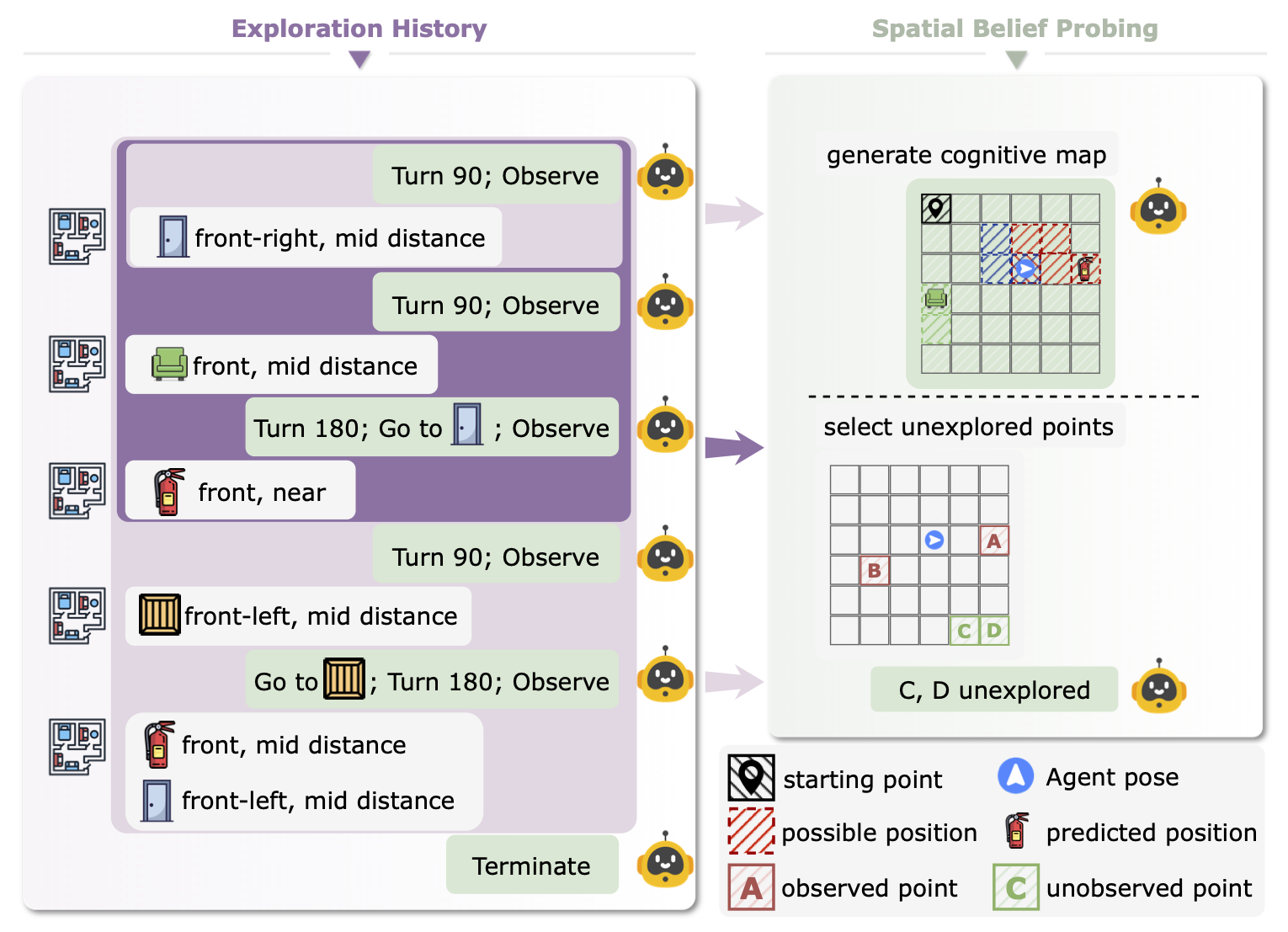
Spatial belief probing: externalize a cognitive map and identify unexplored regions.
We provide a direct window into the agent's spatial belief via explicit cognitive-map probing:
- Agent outputs a structured cognitive map (N×M grid) at each step
- Scored on correctness (ground-truth alignment) and other dynamic metrics
- Also probes uncertainty by identifying unobserved regions
Evaluation Results
Performance comparison of different models on Theory of Space (ToS) benchmark. Dark highlighting indicates the best result within each category, light highlighting denotes the second-best.
Performance Conclusion
Spatial Belief Probing
We probe the agent's internal belief state to understand why failures occur.
- Correctness (final): Evaluates the predicted global map at the last turn.
- Perception: Compares the predicted local map to the ground-truth local map for the current field of view.
- Self-tracking: Compares the agent pose inferred from the predicted global map to the ground-truth agent state.
- Local ↔ Global: Compares local and global predictions within the same turn (coherence check).
- Stability: Checks if previously observed objects degrade in the map over time.
- Uncertainty: Can the agent identify which regions it hasn't seen yet?
| Methods | Correctness | Perception | Local ↔ Global | Stability | Self-tracking | Uncertainty | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Ori. | Pos. | Overall | Ori. | Pos. | Ori. | Pos. | Ori. | Pos. | Ori. | Pos. | ||
| Vision-based World | ||||||||||||
| GPT-5.2 | 20.2 | 42.0 | 32.2 | 33.5 | 72.4 | 57.9 | 58.7 | 65.4 | 56.4 | 93.3 | 64.7 | 53.7 |
| GEMINI-3 PRO | 32.2 | 62.5 | 52.1 | 43.8 | 68.5 | 52.9 | 68.3 | 61.8 | 62.0 | 98.8 | 73.9 | 70.2 |
| Text-based World | ||||||||||||
| GPT-5.2 | 91.0 | 75.1 | 80.0 | 100 | 86.8 | 96.4 | 86.0 | 96.7 | 67.6 | 98.0 | 86.7 | 64.5 |
| GEMINI-3 PRO | 92.5 | 75.5 | 81.4 | 99.9 | 88.2 | 91.6 | 84.8 | 90.8 | 67.7 | 99.9 | 85.2 | 79.2 |
Probing Conclusion
Belief Revision Task
We introduce a dynamic perturbation task to probe the agent's ability to handle non-stationarity. After exploration, 4 objects are secretly relocated/reoriented. The agent must re-explore to identify changes.
- Identification Accuracy: F1 score for correctly identifying which objects changed.
- Average Steps: Cost of belief revision. Includes Redundancy (steps taken after finding all changes).
- Belief Correctness: Map accuracy on the changed objects.
- Belief Inertia: Measures if the agent overwrites its old map (high score) or exhibits belief inertia (low score).
| Methods | Avg. Steps ↓ | Identification (%) ↑ | Belief Correctness (%) ↑ | Belief Inertia (%) ↓ | ||||
|---|---|---|---|---|---|---|---|---|
| All | Red. | Ori. | Pos. | Ori. | Pos. | Ori. | Pos. | |
| Text-based World | ||||||||
| GPT-5.2 | 6.92 | 0.55 | 97.9 | 98.4 | 89.5 | 69.7 | 5.5 | 12.5 |
| GEMINI-3 PRO | 7.79 | 0.18 | 98.7 | 98.8 | 91.8 | 72.9 | 7.9 | 5.7 |
| Vision-based World | ||||||||
| GPT-5.2 | 13.06 | 6.20 | 14.3 | 68.0 | 16.7 | 42.9 | 68.9 | 34.7 |
| GEMINI-3 PRO | 10.29 | 3.23 | 23.9 | 82.5 | 30.3 | 63.1 | 51.1 | 14.4 |
Belief Revision Conclusion
Key Findings
01 Modality Gap
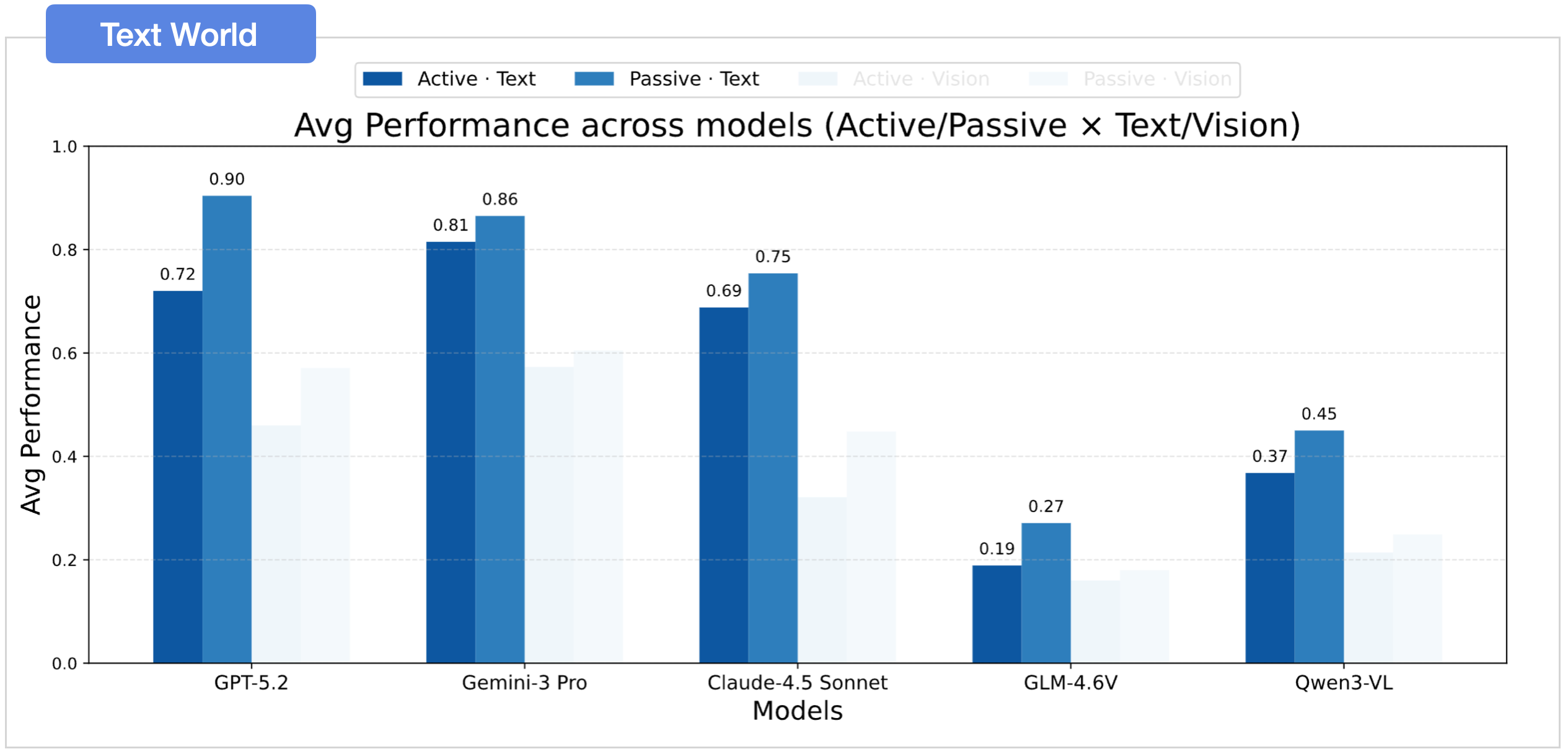
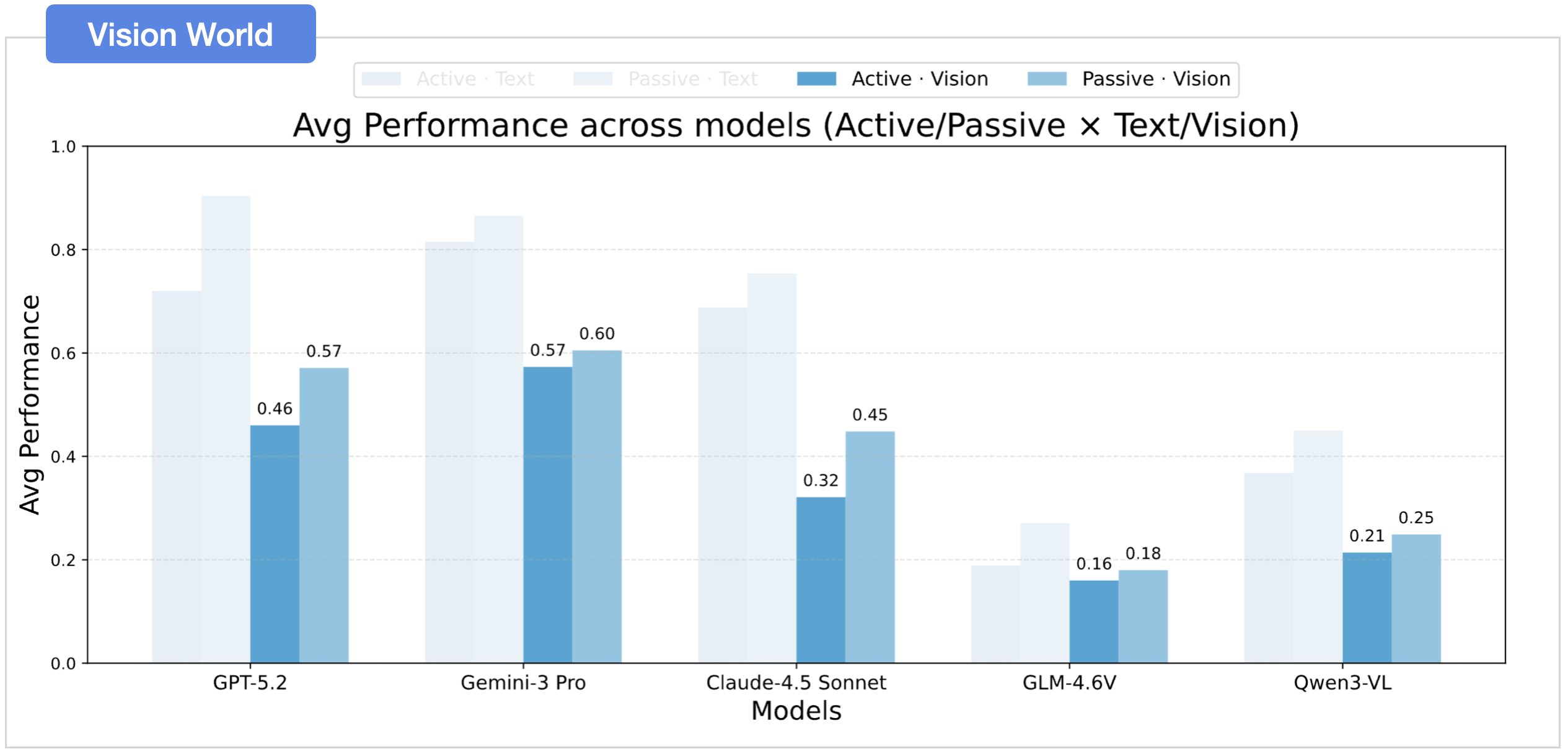
Text significantly outperforms vision.
Modality Gap
Text significantly outperforms vision.
A clear modality gap persists: text-based settings consistently outperform vision-based settings in spatial belief construction and exploitation.
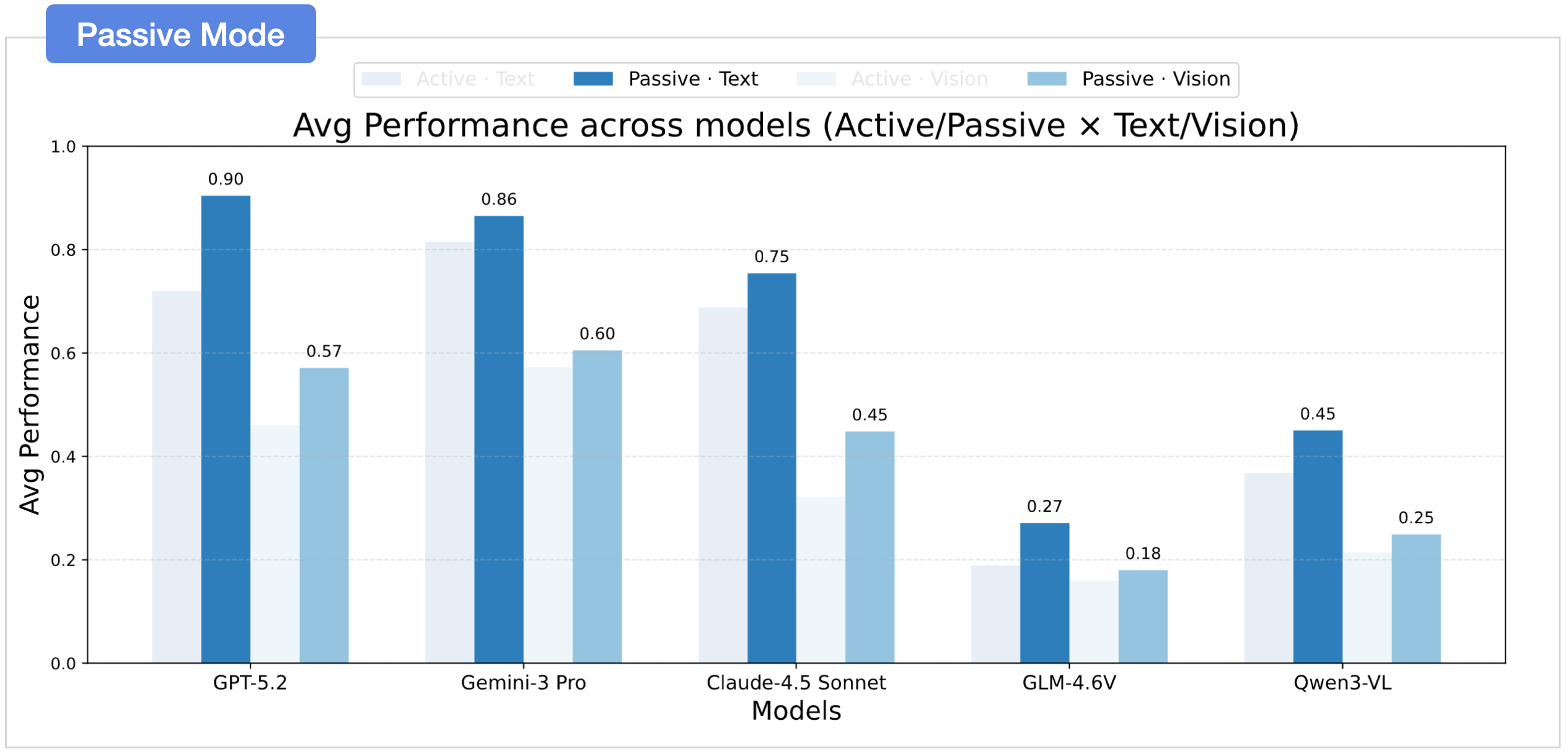
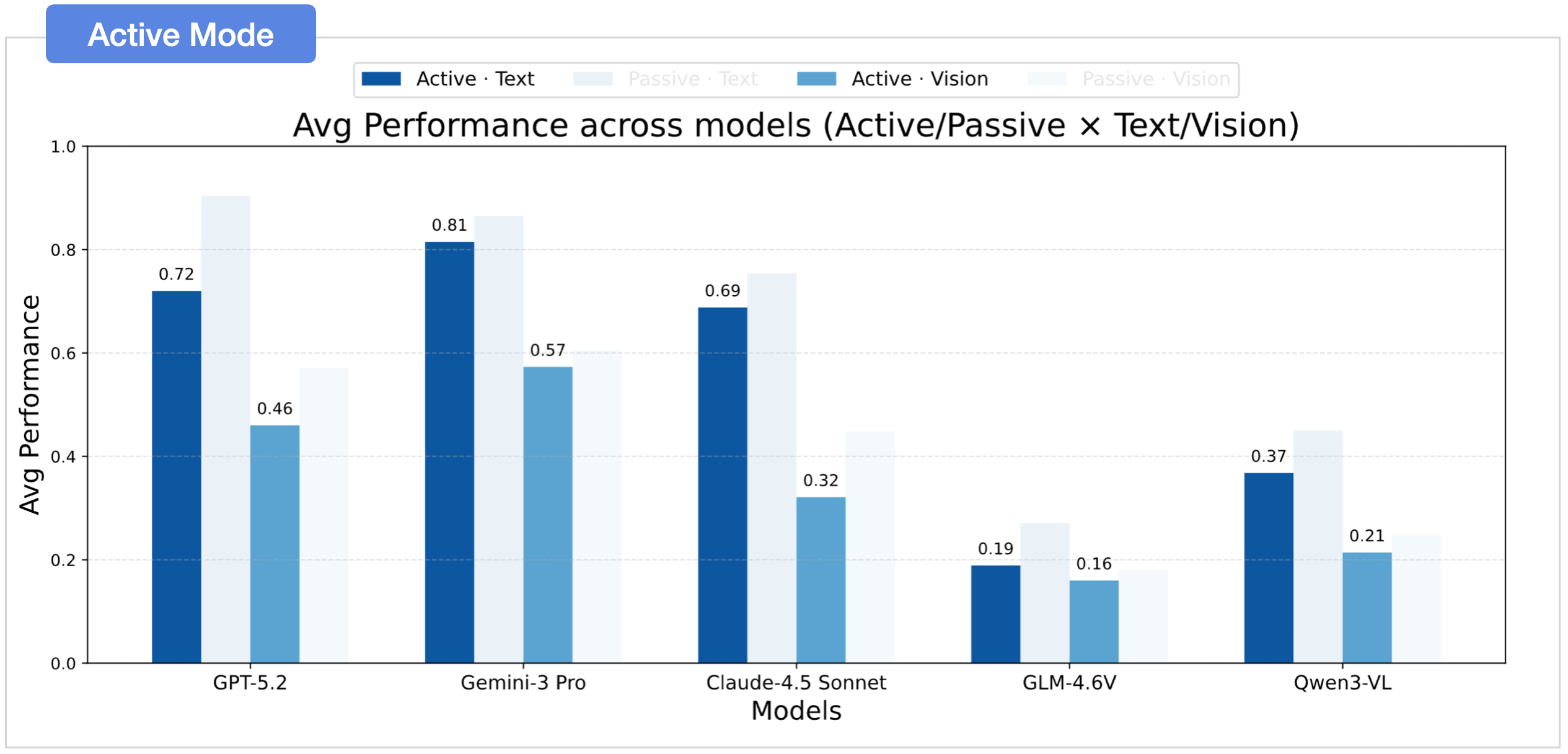
02 Active Exploration is the Bottleneck
Performance drops when models must actively explore.
Active Exploration is the Bottleneck
Performance drops when models must actively explore.
a) Performance and Efficiency Deficit
Active agents score lower than reasoning on rule-based program histories, and explore less efficiently than the program.
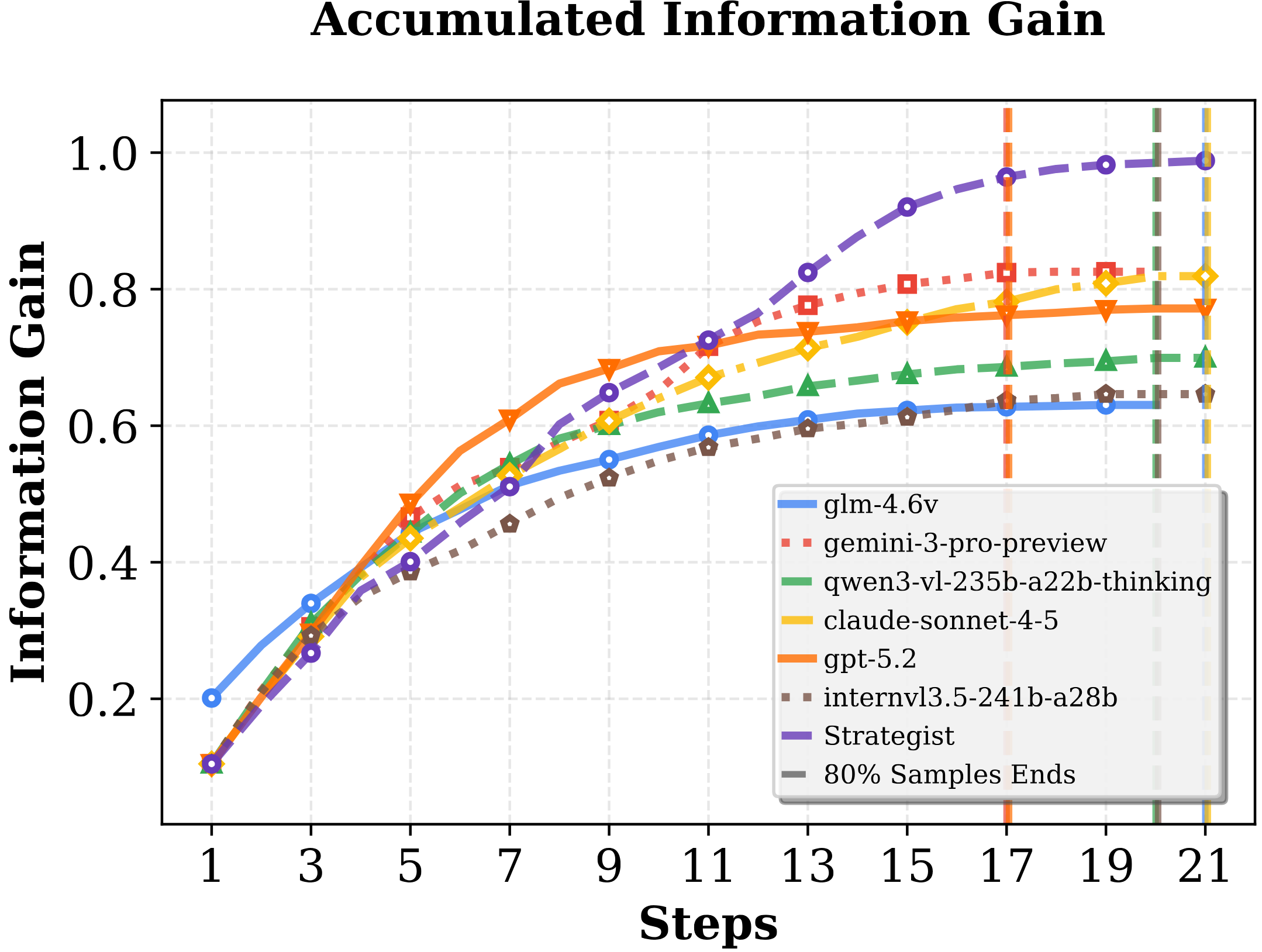
b) Incomplete Coverage
Active agent fails to achieve complete information coverage. Models explore redundantly, requiring ≥14 steps without improving belief accuracy, while rule-based proxies reach target coverage in ~9 steps.
c) Complexity-Widened Gap
The active–passive gap increases with complexity; Gemini-3 Pro scales much better. As the number of rooms increases, exploration cost rises accordingly. For both GPT-5.2 and Gemini-3 Pro, performance declines as the room number increases, and the active–passive performance gap widens with room number.
| Methods | 2-room | 4-room | ||||
|---|---|---|---|---|---|---|
| pass. | act. | exp. | pass. | act. | exp. | |
| Text-based World | ||||||
| GPT-5.2 | 92.3 | 77.8 | 6.2 | 86.5 | 66.0 | 16.4 |
| Gemini-3 Pro | 86.7 | 80.6 | 6.2 | 81.2 | 77.7 | 19.7 |
| Vision-based World | ||||||
| GPT-5.2 | 59.3 | 51.5 | 10.8 | 52.6 | 40.3 | 23.2 |
| Gemini-3 Pro | 58.3 | 57.8 | 6.6 | 56.2 | 51.5 | 19.7 |
03 Cognitive Map Failures
Orientation, stability, and belief drift issues.
Cognitive Map Failures
Orientation, stability, and belief drift issues.
- Orientation Gap: Vision perception is a bottleneck, especially for object orientation.
- Unstable Map: Beliefs about previously observed objects degrade over time.
- Belief Drift: New updates corrupt earlier correct perceptions, lowering final correctness.
04 Maps as a Diagnostic Proxy
Map correctness correlates with downstream success.
Maps as a Diagnostic Proxy
Map correctness correlates with downstream success.
- Sufficiency Test: Conditioning on ground-truth maps yields near-perfect accuracy (~95%), confirming the JSON map format captures all necessary information for tasks.
- Alignment Test: Prompting models to explicitly generate maps before answering slightly degrades performance. This externalization gap indicates the model's latent internal belief is richer than its discretized JSON output.
While lossy, the explicit map remains a strong diagnostic proxy. Map correctness correlates significantly with downstream success:
| Methods | Text (%) | Vision (%) |
|---|---|---|
| GPT-5.2 | 41.8 | 57.0 |
| Gemini-3 Pro | 46.6 | 64.5 |
Pearson correlation (r) between spatial-belief correctness and downstream evaluation performance. All correlations are significant (p<.001).
05 Vision Deficiencies & Belief Inertia
Vision agents persist in obsolete beliefs.
Vision Deficiencies & Belief Inertia
Vision agents persist in obsolete beliefs.
- Vision-based Revision Failures: Vision agents suffer from excessive exploration redundancy and poor accuracy in identifying object shifts.
- Belief Inertia: Agents, especially vision-based ones, persist in obsolete spatial coordinates despite new observations.
Citation
If you find our work useful in your research, please cite:
@inproceedings{zhang2026theoryofspace,
title = {Theory of Space: Can Foundation Models Construct Spatial Beliefs through Active Exploration?},
author = {Zhang, Pingyue and Huang, Zihan and Wang, Yue and Zhang, Jieyu and Xue, Letian and Wang, Zihan and Wang, Qineng and Chandrasegaran, Keshigeyan and Zhang, Ruohan and Choi, Yejin and Krishna, Ranjay and Wu, Jiajun and Fei-Fei, Li and Li, Manling},
booktitle = {International Conference on Learning Representations (ICLR)},
year = {2026},
}